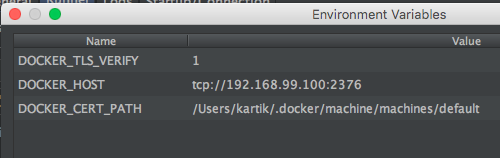
This post is a walkthrough for getting Kubernetes environment up and running. (Truly speaking, it is more of a self note to get Kubernetes environment running.) We will use Vagrant as Kubernetes provider to configure a Kubernetes cluster of VirtualBox VMs.
Prerequisities
Get following componentes installed:
- Kubernetes
- Virtualbox
- Vagrant
- Docker
Step 1: Configure and start Kubernetes
Note: One change I had to make with Kubernetes 1.3.3 running on Mac using Vagrant as Kubernetes provider is to instruct Vagrant to not create ssh keys. I modified the Vagrantfile in kubernetes install by adding
config.ssh.insert_key = falseTo start a Kubernetes cluster
export KUBERNETES_PROVIDER=vagrant export NUM_NODES=2 cluster/kube-up.sh
This will create three VirtualBox images namely master, node-1 and node-2. At the end of the process you will see messages on console like this.
Kubernetes cluster is running. The master is running at: https://10.245.1.2 Administer and visualize its resources using Cockpit: https://10.245.1.2:9090 For more information on Cockpit, visit http://cockpit-project.org The user name and password to use is located in /Users/kartik/.kube/config ... calling validate-cluster Found 2 node(s). NAME STATUS AGE kubernetes-node-1 Ready 4m kubernetes-node-2 Ready 44s Validate output: NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy {"health": "true"} etcd-1 Healthy {"health": "true"} Cluster validation succeeded Done, listing cluster services: Kubernetes master is running at https://10.245.1.2 Heapster is running at https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/heapster KubeDNS is running at https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/kube-dns kubernetes-dashboard is running at https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/kubernetes-dashboard Grafana is running at https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana InfluxDB is running at https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/monitoring-influxdb To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Step 2: Run Docker image
Let’s start a simple Docker image. I will use the Spring Boot application Docker image that we create in the last blog entry - Setting up development environment with Docker, Maven and IntelliJ
To configure the authentication for Docker private repository
docker login [server] This will create credentials under your $HOME/.docker/config.json
To start docker image that is available locally on Docker
kubectl run options --image=kartikshah/options-analyzer --replicas=2 --port=8080 deployment "options" created
It will take a minute or so for the pods to get to Running status. If you catch them in act of starting up you will see ContrainerCreating Status.
$ kubectl get pods NAME READY STATUS RESTARTS AGE options-2554117421-5dwws 0/1 ContainerCreating 0 11s options-2554117421-7ec17 0/1 ContainerCreating 0 11s $ kubectl get pods NAME READY STATUS RESTARTS AGE options-2554117421-5dwws 1/1 Running 0 4m options-2554117421-7ec17 1/1 Running 0 4m
You can validate docker process is running by
$ vagrant ssh node-1 -c 'sudo docker ps' CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1b56f4a3222a kartikshah/options-analyzer "java -Djava.security" 3 minutes ago Up 3 minutes k8s_options.e44b7492_options-2554117421-5dwws_default_b7a648ff-5a58-11e6-9527-08002769954a_0da80b48
Step 3: Find IP address of the node
Describe all to find the IP address of the node.
$ kube describe all … Name: options-2554117421-7ec17 Namespace: default Node: kubernetes-node-2/10.245.1.4 Start Time: Thu, 04 Aug 2016 10:32:56 -0500 Labels: pod-template-hash=2554117421 run=options Status: Running IP: 10.246.21.3 …
The IP address listed agains “IP” is the IP address this node is known inside the cluster. You can run a simple curl command from inside the node
$ vagrant ssh node-1 -c 'curl http://10.246.21.3:8080/' Hello Options Trader, how are you? Connection to 127.0.0.1 closed.
Step 4: Expose Service Loadbalancer
Now let’s expose the pods running on both nodes using a LoadBalancer. Kubernetes load balancer are deployed as Replication Controller (or newer Replication Set). There are three types of Load Balancer options:
1. ClusterIP - Exposes an IP only available from within Kubernetes Cluster
2. NodePort - Exposes special port on a special node IP, but load balances across nodes.
3. LoadBalancer - Only provided by cloud providers e.g. Google, AWS, OpenShift
There is active development going on providing the LoadBalancer option on bare metal Kubernetes deployment. You can read more about it here at service-loadbalancer
We will use NodePort type of replication set to expose as service to outside world.
$ kubectl expose rs options-2554117421 --port=8080 --target-port=8080 --name=option-service --type=NodePort service "option-service" exposed
Describe the service to get node ip and port that is exposed to host machine.
$ kubectl describe service … Name: option-service Namespace: default Labels: pod-template-hash=2554117421 run=options Selector: pod-template-hash=2554117421,run=options Type: NodePort IP: 10.247.237.53 Port: 8080/TCP NodePort: 30728/TCP Endpoints: 10.246.21.3:8080,10.246.33.5:8080 Session Affinity: None ...
Now you can access the service from you host machine. In my case from the Mac which is running the VirtualBox VMs.
$ curl http://10.245.1.4:30728/ Hello Options Trader, how are you?
There you have it - a Kubernetes cluster running a Docker image across multiple VMs (nodes) with NodePort loadbalancing.
Step 5: Console
This step is optional. If you want to explore the Kubernetes dashboard UI, you have to setup a private certificate. One of the ways Kubernetes dashboard UI authenticates is via identity cert. You can create this identity cert as follows:
#Copy the certs from master node vagrant ssh master-c 'sudo cp /srv/kubernetes/kubecfg.* /vagrant/ && sudo cp /srv/kubernetes/ca.crt /vagrant/' #Move them to separate folder mv kubecfg.* ../certs/ && mv ca.crt ../certs/ #Create private cert using open ssl openssl pkcs12 -export -clcerts -inkey ../certs/kubecfg.key -in ../certs/kubecfg.crt -out kubecfg.p12 -name "ks-kubecfg” #For Mac only; open the private cert to install it in Keychain Access open kubecfg.12
Now you can visit the dashboard by visiting the URL provided at the startup message.
https://10.245.1.2/api/v1/proxy/namespaces/kube-system/services/kubernetes-dashboard